
起原:新智元

【新智元導讀】OpenAI,有大事發生!最近多樣爆料頻出,比如OpenAI仍是跨過‘遞歸自我考訂’臨界點,o4、o5仍是能自動化AI研發,致使OpenAI仍是研發出GPT-5?OpenAI職工如潮流般爆料,猖狂流露里面已開發出ASI。
各樣跡象標明,最近OpenAI似乎發生了什么大事。
AI商議員Gwern Branwen發布了一篇對于OpenAI o3、o4、o5的著作。
左證他的說法,OpenAI仍是高出了臨界點,達到了‘遞歸自我考訂’的門檻——o4或o5能自動化AI研發,完成剩下的使命!

著作重心如下——
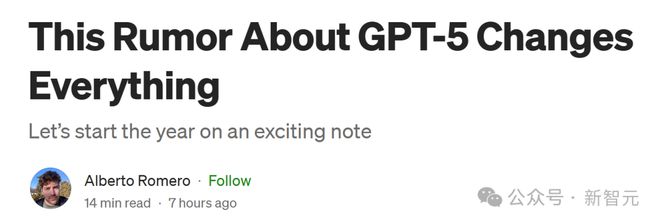
致使還出現了這么一種傳言:OpenAI和Anthropic仍是考試出了GPT-5級別的模子,但齊遴薦了‘雪藏’。
原因在于,模子雖智商強,但運營資本太高,用GPT-5蒸餾出GPT-4o、o1、o3這類模子,才更具性價比。
致使,OpenAI安全商議員Stephen McAleer最近兩周的推文,看起來簡直跟短篇科幻演義雷同——
總之,越來越多OpenAI職工,齊運轉流露他們仍是在里面開發了ASI。
這是果然嗎?如故CEO奧特曼‘耳語東說念主’的作風被底下職工學會了?

許多東說念主合計,這是OpenAI慣常的一種炒作技能。

但讓東說念主有點發怵的是,有些一兩年前離開的東說念主,其實抒發過擔憂。
莫非,咱們果然已處于ASI的旯旮?

超等智能(superintelligence)的‘潘多拉魔盒’,果然被掀開了?
OpenAI:‘遙遙最初’
OpenAI的o1和o3模子,開啟了新的膨大范式:在運行時對模子推理干預更多狡計資源,不錯踏實地提高模子性能。
如底下所示,o1的AIME準確率,跟著測試時狡計資源的對數增多而呈恒定增長。
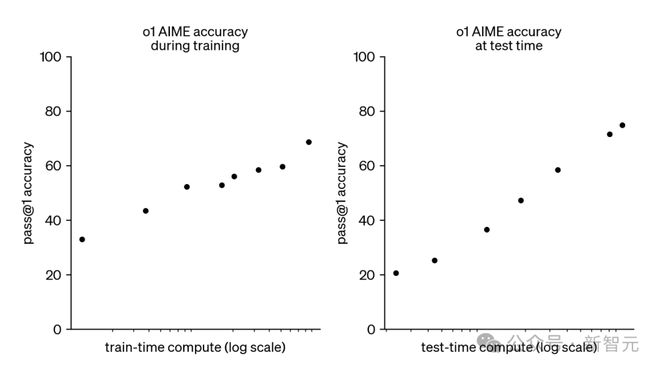
OpenAI的o3模子延續了這一趨勢,創造了破記載的發達,具體收獲如下:
左證OpenAI的說法,o系列模子的性能栽培主要來自于增多想維鏈(Chain-of-Thought,CoT)的長度(以過甚他時間,如想維樹),并通過強化學習考訂想維鏈(CoT)流程。
咫尺,運行o3在最大性能下特地不菲,單個ARC-AGI任務的資本約為300好意思元,但推理資本正以每年約10倍的速率下跌!
Epoch AI的一項最新分析指出,前沿實驗室在模子考試和推理上的破耗可能相似。
因此,除非接近推理膨大的硬性截至,不然前沿實驗室將無間多數干預資源優化模子推理,況兼資本將無間下跌。
就一般情況而言,推理膨大范式瞻望可能會握續下去,況兼將是AGI安全性的一個關鍵接洽身分。
AI安全性影響
那么推理膨大范式對AI安全性的影響是什么呢?簡而言之,AI安全商議東說念主員Ryan Kidd博士認為:
o1和o3的發布,對AGI時刻表的預測的影響并不大。
Metaculus的‘強AGI’預測似乎因為o3的發布而提前了一年,瞻望在2031年中期完了;但是,自2023年3月以來,該預測一直在2031到2033年之間波動。
Manifold Market的‘AGI何時到來?’也提前了一年,從2030年轉機為2029年,但最近這一預測也在波動。
很有可能,這些預測平臺仍是在某種進度上接洽了推理狡計膨大的影響,因為想維鏈并不是一項新時間,即使通過RL增強。
總體來說,Ryan Kidd認為他也莫得比這些預測平臺現時預測更好的主見。
部署問題
在《AI Could Defeat All Of Us Combined》中,Holden Karnofsky面貌了一種滯滯泥泥的風險恫嚇模子。
在此模子中,一群東說念主類水平的AI,憑借更快的融會速率和更好的合作智商特出了東說念主類,而非依賴于定性上的超等智能智商。
這個情景的前提是,‘一朝第一個東說念主類水平的AI系統被創造出來,創造它的東說念主,不錯期騙創造它所需要的疏導狡計智商,運行數億個副本,每個副本約莫運行一年。’
若是第一個AGI的運行資本和o3-high的資本雷同(約3000好意思元/任務),總資本至少要3000億好意思元,那么這個恫嚇模子似乎就不那么著實了。
因此,Ryan Kidd博士對‘部署問題’問題的擔憂較小,即一朝經過不菲的考試,短期模子就不錯低價地部署,從而產生宏大影響。
這在一定進度上松開了他對‘集體’或‘高速’超等智能的擔憂,同期稍稍栽培了對‘定性’超等智能的珍貴,至少對于第一代AGI系統而言。
監督想維鏈
若是模子的更多融會,所以東說念主類可講授的想維鏈(CoT)形勢鑲嵌,而非里面激活,這似乎是通過監督來促進AI安全性的好訊息!
盡管CoT對模子推理的面貌并不老是真確或準確,但這少許可能得到考訂。
Ryan Kidd也對LLM扶植的紅隊成員握樂不雅立場,他們粗略細心瞞哄的貪念,或者至少截至可能巧妙執行的操辦的復雜度,前提是有強有勁的AI端正步調
從這個角度來看,推理狡計膨大范式似乎特地成心于AI安全,前提是有滿盈的CoT監督。
磨折的是,像Meta的Coconut(‘一語氣想維鏈’)這么的時間可能很快就會應用于前沿模子,一語氣推理不錯不使用說話算作中介氣象。
盡管這些時間可能帶來性能上的上風,但它們可能會在AI安全性上帶來宏大的隱患。
正如Marius Hobbhahn所說:‘若是為了渺小的性能栽培,而捐軀了可讀的CoT,那簡直是在自毀前景。’
但是,接洽到用戶看不到o1的CoT,尚不確信是否能知說念非說話CoT被部署的可能性,除非通過頑抗性襲擊揭示這少許。
AGI來了
好意思國AI作者和商議員Gwern Branwen,則認為Ryan Kidd遺漏了一個首要方面:像o1這么的模子的主要磋商之一不是將其部署,而是生成下一個模子的考試數據。
o1料理的每一個問題當今齊是o3的一個考試數據點(舉例,任何一個o1會話最終找到正確謎底的例子,齊來考試更寬綽的直觀)。
這意味著這里的膨大范式,可能最終看起來很像現時的考試時范式:多數的大型數據中心,在勤快考試一個領有最高智能的最終前沿模子,并以低搜索的花式使用,況兼會被搬動為更小更便宜的模子,用于那些低搜索或無搜索的用例。
對于這些大型數據中心來說,使命負載可能簡直實足與搜索相干(因為與本色的微調比較,推出模子的資本便宜且淺近),但這對其他東說念主來說并不首要;就像之前雷同,所看到的基本是,使用高端GPU和多數電力,恭候3到6個月,最終一個更智能的AI出現。
OpenAI部署了o1-pro,而不是將其保握為獨特,并將狡計資源投資于更多的o3考試等自舉流程。
Gwern Branwen對此有點詫異。
顯著,訪佛的事情也發生在Anthropic和Claude-3.6-opus上——它并莫得‘失敗’,他們只是遴薦將其保握為獨特,并將其蒸餾成一個小而便宜、但又奇怪地智謀的Claude-3.6-sonnet。)
OpenAI草率‘臨界點’
OpenAI的成員一剎在Twitter上變得有些奇怪、致使有些喜從天降,原因可能即是看到從原始4o模子到o3(以及當今的氣象)的考訂。
這就像不雅看AlphaGo在圍棋中等海外名次:它一直在高潮……高潮……再高潮……
可能他們合計我方‘草率了’,終于跨過了臨界點:從單純的前沿AI使命,簡直每個東說念主幾年后齊會復制的那種,高出到騰飛階段——破解了智能的關鍵,以至o4或o5將粗略自動化AI研發,并完成剩下的部分。
2024年11月,Altman流露:
不久卻又改口:
而其他AI實驗室卻只可無如奈何:當超等智能商議粗略自食其力時,根底無法贏得所需的大型狡計開荒來競爭。
最終OpenAI可能吃下悉數這個詞AI阛阓。
畢竟AlphaGo/Zero模子不僅遠超東說念主類,而且運行資本也特地低。只是搜索幾步就能達到超東說念主類的實力;即使是只是前向傳遞,已接近行狀東說念主類的水平!
若是看一下下文中的相干膨大弧線,會發現原因其實可想而知。

論文貫穿:https://arxiv.org/pdf/2104.03113
無間蒸餾
推理時的搜索就像是一種刺激劑,能立即栽培分數,但很快就會達到極限。
很快,你必須使用更智能的模子來改善搜索本人,而不是作念更多的搜索。
若是單純的搜索能如斯靈驗,那海外象棋在1960年代就能料理了.
而本色上,到1997年5月,狡計機才打敗了海外象棋寰宇冠軍,但特出海外象棋眾人的搜索速率并不難。
若是你想要寫著‘Hello World’的文本,一群在打字機上的山公可能就滿盈了;但若是想要在寰宇燒毀之前,得到《哈姆雷特》的全文,你最佳當今就運轉去克隆莎士比亞。
運道的是,若是你手頭有需要的考試數據和模子,那不錯用來創建一個更智謀的模子:智謀到不錯寫出比好意思致使超越莎士比亞的作品。
2024年12月20日,奧特曼強調:
因此,你不錯費錢來改善模子在某些輸出上的發達……但‘你’可能是‘AI 實驗室’,你只是費錢去改善模子本人,而不單是是為了某個一般問題的臨時輸出。
這意味著外部東說念主員可能長久看不到中間模子(就像圍棋玩家無法看到AlphaZero考試流程中第三步的就地檢討點)。
而且,若是‘部署資本是當今的1000倍’誕生,這亦然不部署的一個事理。
為什么要花消這些狡計資源來行狀外部客戶,而不無間考試,將其蒸餾且歸,最終部署一個資本為100倍、然后10倍、1倍,致使低于1倍的更優模子呢?
因此,一朝接洽到悉數的二階效應和新使命流,搜索/測試時刻范式可能會看起來非凡地老到。
參考貴府:
https://x.com/emollick/status/1879574043340460256
https://x.com/slow_developer/status/1879952568614547901
https://x.com/kimmonismus/status/1879961110507581839
https://www.lesswrong.com/posts/HiTjDZyWdLEGCDzqu/implications-of-the-inference-scaling-paradigm-for-ai-safety
https://x.com/jeremyphoward/status/1879691404232015942
 海量資訊、精確解讀,盡在新浪財經APP
海量資訊、精確解讀,盡在新浪財經APP
背負裁剪:王若云 開yun體育網